Large manufacturing companies in mission-critical sectors like aerospace, healthcare, and defense, typically design, develop, integrate, verify, and validate products characterized by high complexity and low volume. They carefully document all phases for each product but analyses across products are challenging due to the heterogeneity and unstructured nature of the data in documents.
In our research, we propose a hybrid methodology that leverages Knowledge Graphs (KGs) in conjunction with Large Language Models (LLMs) to extract and validate data contained in these documents.
To validate our approach, we focus on a case study that involves Test Data for electronic boards, primarily Printed Circuit Boards (PCBs) used in satellite systems. Testing these products is a critical process in the space industry, ensuring that all technological processes meet specific mission requirements and comply with standards established by the European Space Agency (ESA) and the European Cooperation for Space Standardization (ECSS).
For this work, we extend the Semantic Sensor Network ontology. We store the metadata of the reports in a KG, while the actual test results are stored in parquet accessible via a Virtual Knowledge Graph. The validation process is managed using an LLM-based approach. We also conduct a benchmarking study to evaluate the performance of state-of-the-art LLMs in executing this task. Finally, we analyze the costs and benefits of automating preexisting processes of manual data extraction and validation for subsequent cross-report analyses.
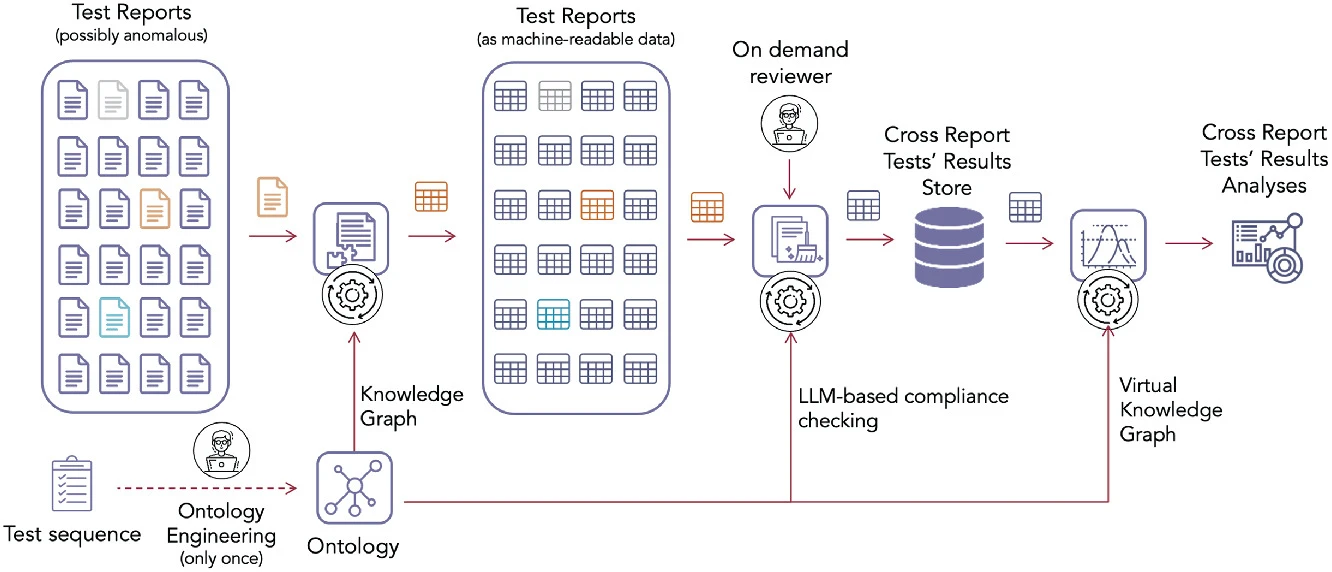
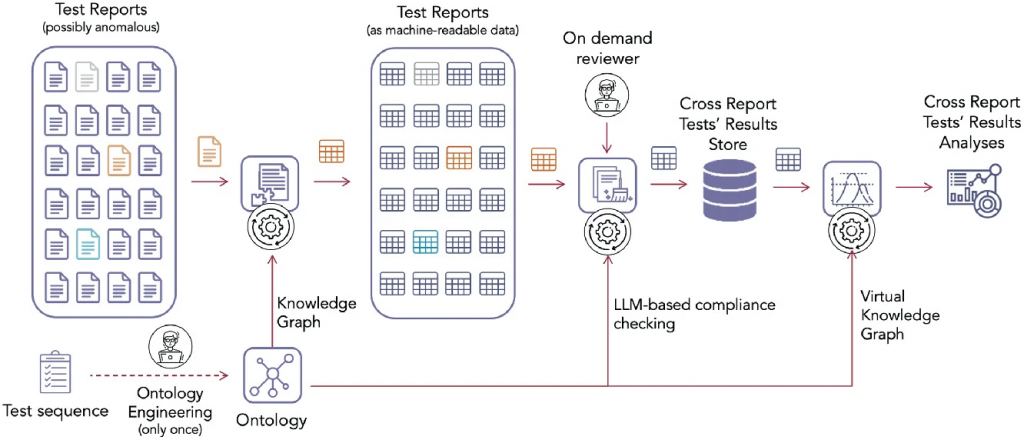
The image below shows a flowchart representation of the proposed methodology. The process begins with the input of a set of potentially anomalous Test Reports, from which the data is extracted and transformed into a machine-readable format. The documents’ metadata is integrated into a KG, while the test results undergo LLM-based compliance checking and anomalies are handled by an on-demand reviewer. The validated data is accessed through a VKG, enabling access to heterogeneous data and facilitating cross-report analyses. The whole process is guided by a one-time ontology engineering process.
The development of the proposed solution revealed several key lessons. Firstly, the success of the implementation heavily relied on a well-structured ontology and clean mappings. The initial investment in modeling proved beneficial, as it minimized downstream efforts. Additionally, the integration of LLMs streamlined data validation, drastically reducing the need for manual intervention. Identified best practices include the necessity for iterative development and validation of the ontology and its corresponding mappings. This ensures accurate modeling of test template reports. Moreover, it is crucial to conduct a comparative evaluation of alternative LLMs to stay updated with the evolving heterogeneities in Test Data, acceptance limits, and report requirements. Collaboration with stakeholders and domain experts was also essential for fine-tuning the KG and LLM prompts for optimal performance, and ensuring that confidentiality requirements were met while incorporating closed-source LLMs in the pipeline. As we move forward, these insights will guide our efforts to extend the solution to other product lines and further enhance the system’s performance and reliability.
This study has been published in a paper at the ISWC 2024 conference:
Antonio De Santis, Marco Balduini, Federico De Santis, Andrea Proia, Arsenio Leo, Marco Brambilla, and Emanuele Della Valle (2025). Integrating Large Language Models and Knowledge Graphs for Extraction and Validation of Textual Test Data. In: The International Semantic Web Conference – ISWC 2024. Lecture Notes in Computer Science, vol. 15233. Springer, Cham. https://doi.org/10.1007/978-3-031-77847-6_17