
In aerospace engineering, ensuring that electronic components are properly qualified is essential for safety and mission success. However, in large organizations, qualification data is often fragmented across multiple systems, making retrieval slow, error-prone, and expensive.
In this story, I would like to report on our study in the industrial context of Thales Alenia Space that tackles this problem by combining Large Language Models (LLMs) with Virtual Knowledge Graphs (VKGs) to integrate and query heterogeneous data sources efficiently.
This study has been published and presented at the 23rd European Semantic Web Conference (ESWC 2026), Dubrovnik, Croatia, May 10–14, 2026. The full article is published by Springer and is accessible here: LLM-Enhanced Semantic Data Integration of Electronic Component Qualifications in the Aerospace Domain
The Challenge
Due to data silos, designers cannot immediately determine the qualification status of individual components. However, this process is critical during the planning phase, when assembly drawings are issued before production, to optimize new qualifications and avoid redundant efforts. To address this, we propose a pipeline that uses Virtual Knowledge Graphs for a unified view over heterogeneous data sources and LLMs to enhance retrieval and reduce manual effort in data cleansing. The retrieval of qualifications is then performed through an Ontology-based Data Access approach for structured queries and a vector search mechanism for retrieving qualifications based on similar textual properties. In the scenario we consider, we assume that two main systems are involved:
- A PLM database containing component specifications
- A Qualification Catalog tracking testing and compliance status os such components.
These datasets are inconsistent, partially unstructured, and often require manual cross-referencing. For example, key identifiers like part numbers may be buried in free-text fields, while manufacturer names appear in multiple inconsistent formats. As a result, engineers struggle to determine whether a component has already been qualified, leading to redundant work.
The Approach
The solution introduces a hybrid pipeline with three main steps, as shown in this model:
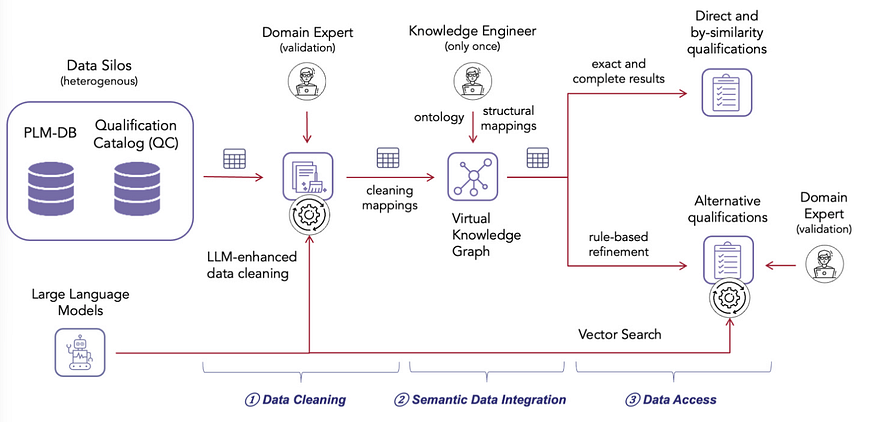
- Data Cleaning with LLMs
LLMs are used to normalize inconsistent data (e.g., manufacturer names) and extract structured information from text, such as part numbers hidden in notes. This significantly reduces manual effort while keeping humans in the loop for validation. - Semantic Integration with VKGs
A Virtual Knowledge Graph provides a unified semantic layer over the original databases without physically merging them. Using ontology-based mappings, engineers can query the data consistently through SPARQL, while the system translates queries into SQL behind the scenes. - Hybrid Retrieval
Retrieval is based on two strategies: Exact matches (direct and similar qualifications) are handled with structured queries; More complex cases use vector embeddings and similarity search to suggest candidates, which are then reviewed by experts.
Why Not Just Use RAG?
The team also evaluated a Retrieval-Augmented Generation (RAG) approach. While faster to implement, RAG showed lower reliability — especially for more complex qualification scenarios — and still required significant human validation.
In contrast, the VKG+LLM approach required more upfront effort but delivered better accuracy and scalability over time .
The system is now deployed in production and used by engineers across multiple departments.
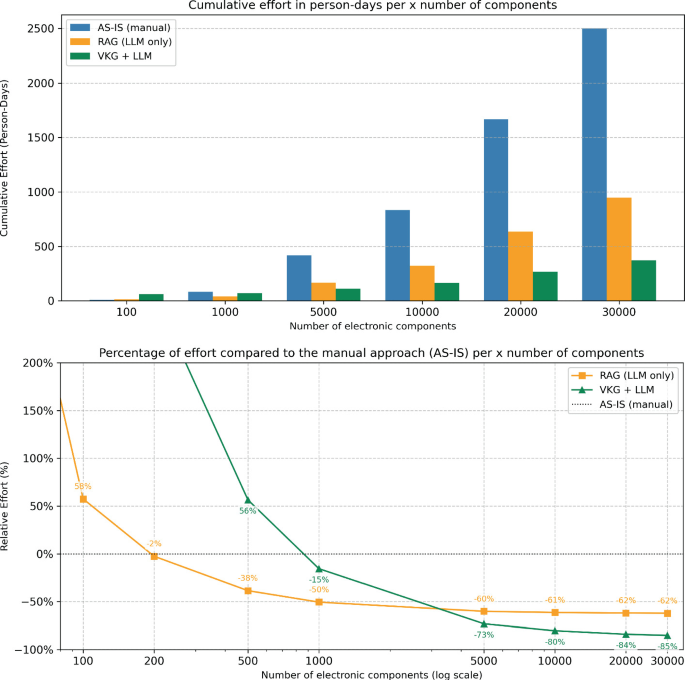
Compared to manual workflows:
- Effort per component dropped from ~40 minutes to ~5 minutes
- Large-scale processing achieved over 80% effort reduction.
Detailed results are reported here:
Key Takeaways
The take-home message from this study is that hybrid approaches outperform purely LLM-based systems in complex industrial settings. In particular:
- LLMs are highly effective for data cleaning and extraction
- Knowledge graphs provide structure, consistency, and precise querying
Therefore, we may say that this work shows that the future of enterprise AI is not purely generative or purely symbolic, but a combination of both.
The full reference to the paper is:
De Santis, A., Balduini, M., Belcao, M., Proia, A., Brambilla, M., Della Valle, E. (2026). LLM-Enhanced Semantic Data Integration of Electronic Component Qualifications in the Aerospace Domain. In: Acosta, M., et al. The Semantic Web. ESWC 2026. Lecture Notes in Computer Science, vol 16550. Springer, Cham. https://doi.org/10.1007/978-3-032-25159-6_21